This post contains related topics and disjointed observations as addenda to “Labour repression & the Indo-Japanese divergence” in cotton textiles.
- (Lack of) Japanese industrial policy in cotton textiles, with a note on Sven Beckert
- Bargaining & capital-labour substitution in cotton textiles
- More on technological divergence in Japan vs India
- Human capital divergence in Japan vs India?
- Exchange rates
- Gupta (2011) on India: coordination failures & rising wage-rental ratios
- Roy (2008) on jobber power at Indian mills
- Learning & Bargaining at New England Mills
- Labour relations in Lancashire & New England
- Labour power in early Lancashire
- Productivity & industrial relations in Lancashire
Japanese industrial policy in cotton textiles, with a note on Sven Beckert
In the India-Japan post, I am not arguing that technology, education, institutions, and trade policy were unimportant in Japan’s industrialisation. But the experience of the Japanese and Indian textile industries also suggests those may have been necessary but not sufficient. India’s lack of competitiveness vis-à-vis Japan in cotton textiles was primarily due to Japan’s comparative advantage in labour market institutions. I don’t see how industrial policy could have worked in India given the militancy of Indian labour.
But I expand on that issue of industrial policy first.
The Japanese cotton textile industry was not, I repeat not, a beneficiary of Japanese industrial policy.
Until 1911, Japan lacked “tariff autonomy”. That is, the “unequal treaties” signed by Japan at the time of its opening to the world in the 1850s prohibited any tariffs beyond a small level designed for revenues.
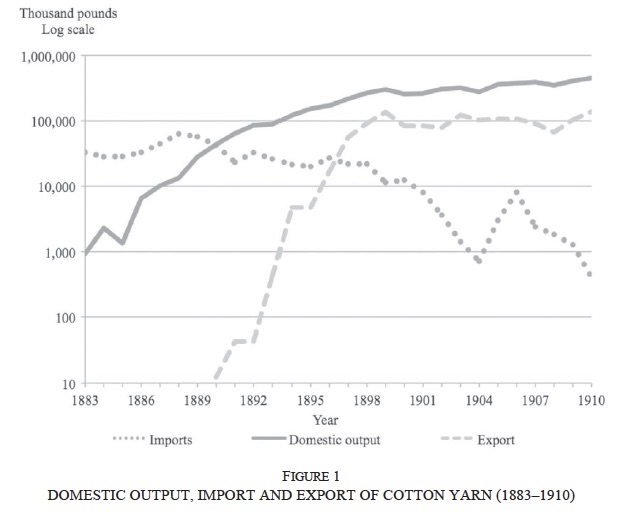
[Source: Braguinsky & Hounshell (2015)]
However, Otsuka, Ranis & Saxonhouse (1988) argue that Japan could still selectively exempt favoured industries from the 5% revenue tariffs. The Japanese cotton spinning firms were granted precisely that exemption — the raw cotton imported from abroad (mostly India and the United States) were allowed in with 0 tariffs instead of 5%. Otsuka et al. then calculate the effective rate of protection on Japanese textiles as a result of this preferential zero-tariff policy. And their estimates run pretty high.
But EPA is not a pure measure of tariff protection. It very generally measures the difference between the domestic supply price of a good and its international price. So it can be ‘contaminated’ by a number of factors, such as monopoly pricing due to cartels within the domestic market, or the layers of markups created by the domestic distribution network. Both elements were present in the case of Japanese spinning.
How about non-tariff industrial policies?
The Japanese government set up and financed model spinning mills between the 1870s and the mid-1880s to promote a national cotton textile industry. But these government-owned and -promoted failed mills and had to be sold off.
Even more importantly, the Japanese government pushed the wrong technology on several fronts.
For the spinning equipment, the government chose mules, which was what Lancashire firms used. But this was a skill-intensive technology not well suited to Japan’s needs. The Japanese government’s promotion programme led the earliest private spinning industry down the wrong road!
Later, private Japanese spinning firms would adopt, literally overnight, the deskilled ring spinning machine. Otsuka, Ranis & Saxonhouse (1988): “By 1891, no firm invested in the mule. In the space of two years, the importation of mules ceased completely. Thus, aided by fires which conveniently destroyed a substantial portion of existing mule stock, a virtually instantaneous switch from mules to rings occurred”.
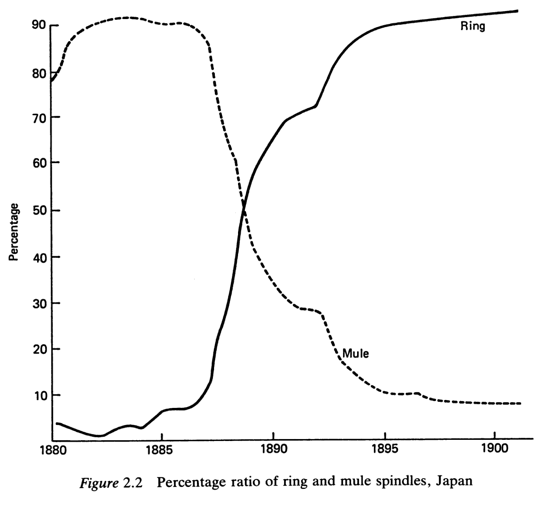
[Source: Otsuka, Ranis & Saxonhouse (1988)]
The Japanese government had chosen the mule, in part, because it wanted to promote Japan’s own domestic short-staple cotton. Short-staples could only be spun with mules. Yet, Braguinsky & Hounshell (2015) says:
The government’s decision to promote the use of Japanese-grown cotton was also misguided. With a staple length of just 5/8 inch (Saxonhouse and Wright 2010, p. 562), Japanese-grown cotton was too short to be effectively transformed into quality yarn using Western machinery.”
Government desires to couple industrial policy and agricultural policy, rather than the ignorance of the technical difficulties, were to blame. The objective of using locally-sourced cotton also led authorities to promote the construction of numerous small-scale (2,000-spindle) mills scattered all over the country, hampering industry development (Takamura 1971, 1:45)”.
This is rather like some Latin American or African import substitution strategy in the 1960s or 1970s. Or the pre-revolutionary Russian textile industry, which was also hampered by the government’s decision to slap foreign cotton imports with high tariffs in order to support raw cotton from Central Asia. Central Asian cotton was expensive by international standards, and not of high quality, but the Russian government had invested too much in making Central Asia a major cotton-growing region.
The Japanese government also pushed for water power, which was also another horrible choice.

In The Empire of Cotton, Sven Beckert makes the following observations about state support of the Japanese cotton textile industry:
From the 1870s, the new nation-state began to pursue a more active policy to promote industry— and cottons were foremost on the new rulers’ minds….”
“From 1879 to the mid-1880s, the minister of home affairs, Ito Hirobumi, expanded domestic spinning capacity by organizing ten spinning mills with two thousand spindles each, importing them from Great Britain, and giving them on favorable terms to local entrepreneurs. These mills failed as commercial enterprises because their scale of production was too small to make them profitable. But unlike their predecessors they introduced new policies that turned into the key factors for the success of Japan’s industrialization: a switch to much cheaper Chinese cotton (in lieu of domestically grown cotton); experimental labor systems that would structure Japanese textile industrialization long into the future (such as the day and night shift system, which gave cost advantages over Indian competitors); and encouragement of government managers to become entrepreneurs themselves. These mills, moreover, created the “ideological roots” of low-wage, harsh-labor regimes, drawing on women whose pay was below subsistence levels, combined with a powerful rhetorical commitment to paternal care, and a transfer of power from samurai and merchants to managers and factory owners.”
Beckert completely fails to note any of the things I’ve mentioned above from Braguinsky & Hounshell and Otsuka et al. In fact, most of the passage is just flim-flam — the idea that the state had to implant the idea of a low-wage advantage or multiple-shifts in the minds of businessmen is just plain stupid.
The only thing of substance in the passage is the part I’ve put in bold. But the choice of Chinese cotton was also an error on the Japanese government’s part, because it worked best with mules and mules were the wrong technology.
When the private Japanese industry threw out the bad technology choices the government had made, it went with ring spinning. And rings worked better with a mix of Indian and American cotton:

[Source: Otsuka, Ranis & Saxonhouse (1988)]
The Japanese textile industry was famous for its innovative multi-continent cotton-mixing, something which apparently never registered with Sven Beckert. That book packs so much information yet misses so many key details!
Note on India
Would infant industry protection have helped Indian cotton? Bagchi (1972) and Gupta (2011) believe tariffs would have helped if they had been used early enough.
Had Britain altruistically closed off the Indian market to import competition, the Indian industry certainly would have been bigger.
Wolcott (1997) estimates the counterfactual size of the Indian textile industry if tariff policy had allowed Indian firms to produce all cloth that had been imported in 1921-38. She estimates that the Indian industry would have achieved its 1938 size by 1927. But the counterfactual size in 1938 would have been 8% higher at best, using generous assumptions.
But the big problem of the Indian textile industry was labour inefficiency, i.e., using too many labour inputs to produce a given unit of output, and this was due to workers’ resistance to handling more machines. Why would a well-protected Indian industry have faced greater incentives or ability to rationalise its work force? I just don’t see how that works.
One might justify industrial policy or tariff protection because a period of learning-by-doing is necessary (i.e., acquisition of skill through experience by both workers and management). But if productivity growth stagnates because workers resist labour intensification and rising capital-labour ratios, then the industry can only expand on the extensive margin, i.e., through a proportionate expansion of both labour and capital inputs. It’s difficult to see how tariffs or other interventionist trade policy could have done anything other than promote the size of the Indian industry without improving its productivity. That is, after all, what actually happened after tariff protection was granted by the British Raj in the interwar period. The industry outside Bombay expanded rapidly but its productivity growth was minimal.
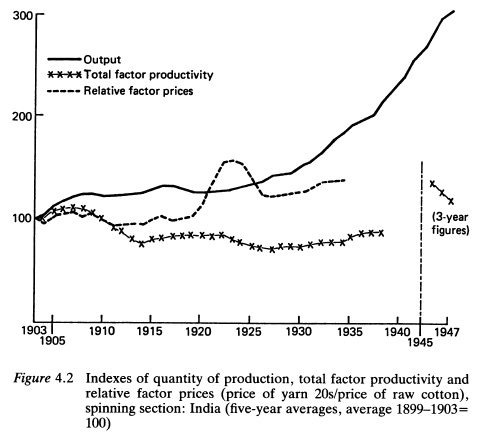
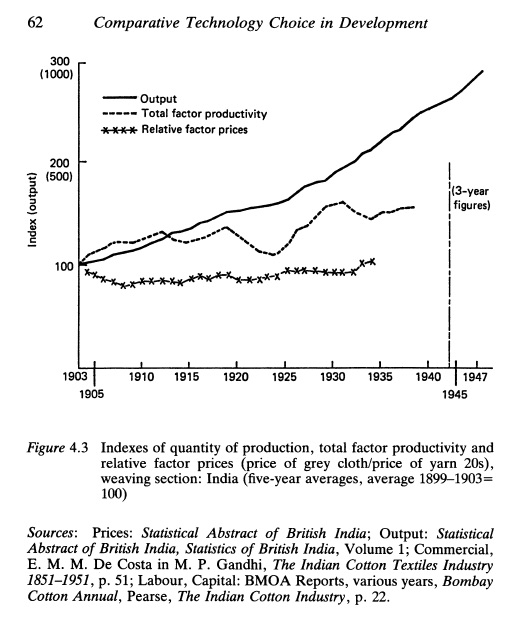
[Source: Otsuka, Ranis & Saxonhouse (1988)] x
Bargaining & capital-labour substitution
(a)
Clark (1987) presents two stylised facts about pre-war cotton textile technology which I believe are supported by subsequent research such as Bessen (2012) and Zeitz (2013):
- At any given point in time, output per machine was approximately the same across countries. Holding product quality constant, you could only vary machine speeds within a limited range.
- There was inherently little scope for factor substitution. If wages were low and costs of capital and raw material were high, you could run your machines a little faster, and you could also use lower-quality raw material. Both of these actions raised labour requirements, but you could only get modest net savings in labour costs per unit of output.
Bessen (2012) also shows that price-driven capital-labour substitution had almost nothing to do with going from 1 loom per weaver to 20 per weaver because the elasticity of substitution was very low in weaving. The technology looks near-Leontieff! Isoquants for weaving at New England mills for the benchmark years 1801, 1819, and 1901:

(b)
With higher wages, all else equal, there exists an incentive to substitute more capital for labour. But in the textile and other industries, this can take the form of (1) investment in improved machinery; or (2) labour intensification through increasing machines per worker, i.e., stretch-out (and possibly also speed-up of machinery).
If the employer has bargaining power in the labour market, the incentive for (b) may be greater than for (1) because it would be cheaper. But you can also have a combination of (1) and (2), because you can intensify labour even more if you have improved (effort-saving) machines.
But there are tradeoffs in making a worker operate more machines. You save on labour costs, but you also run the risk of idling machines more often as a worker can only attend to a single machine at a time when there are problems or errors.
1 loom per weaver => fewer machines idled when worker intervention is required => more likely to reach maximum machine capacity
8 looms per weaver => more machines can be idled => higher risk of losing machine efficiency
Because New England had the highest wages in the world, the trade-off worked in the direction of more machines per worker.
In Lancashire, where even skilled labour was cheaper, power looms per weaver was only about 4.
Wouldn’t it still have made sense for British firms to lower labour costs through work intensification? Yes, but Lancashire also faced much more powerful trade unions than New England. This changed the tradeoffs facing British firms, because the transaction costs of negotiating new wage schedules were very high. And the new wages demanded by unions might have been high enough to offset the labour cost advantages of 6 or 8 looms per worker in England.
From the American point of view, if New England workers had had more market power, it’s plausible that firms could not have made their workers operate more machines at the right cost.
(c)
Gupta (2011) argues that before the (exogenous) rise in real wages caused by the boom of the First World War, the Indian “cotton mill entrepreneur faced little pressure to increase productivity”. After the war, the wage-rental ratio (the ratio of wages to the cost of capital) rose faster in Japan than in India, so there was a greater incentive for Japan to invest in technology.
But Gupta only looks at one dimension of incentives to raise labour productivity and ignores the simple fact that Japanese competitors were stealing away (domestic and export) market share from Indian mills through lower labour costs. That’s an incentive for Indian mills to reduce labour costs, period, regardless of capital costs. If Indian capital costs were not falling as much as in Japan, that simply biases the method of cost savings toward labour intensification rather than investment in new technology. Hence all the calls for rationalisation. As argued in (b), it was cheaper to intensify labour than to invest in new machines anyway, all things equal. x
More on technological divergence in cotton textiles
How much did technological change contribute to the Indo-Japanese divergence in machines per worker in the interwar period?
(1) Rationalisation required no new technology
First, as mentioned in the main post, there were at least 15 Indian mills in the 1920s-30s which did reduce manning ratios substantially. According to Wolcott (1994, 1997) new equipment were not necessary for these changes. Most of the changes were organisational: a matter of getting each worker to handle more machines. But this required paying higher wages for this increase in effort levels than in Japan.
(2) More on automatic looms
Circa 1936 only about 12% of Japan’s looms were automatic (Rose 1991); and the entire weaving sector itself accounted for a relatively small fraction of the value added in Japanese textiles. So automatics just can’t account for the huge disparity between India and Japan in textile labour productivity.
And the Indian workers were unwilling to handle enough automatics. Here’s the full quote from the Indian Tariff Board that I cited in the main post:
Experiments with [the automatic loom] have been made from time to time in Bombay, Ahmedabad, and Sholapur, but the results obtained have not been encouraging…”
“…The additional cost…could only be compensated by higher production, higher prices, or a reduction in labour costs. It does not appear that the production of the Northrop loom is higher than that of the ordinary loom or that any higher price can be obtained for the cloth manufactured on it…. The reduction in labour costs would depend on the number of looms tended by one weaver. In America, one operative attends to 20 to 24 of these looms against 8 to 10 ordinary looms, but the result of the experiments so far made with them in India goes to show that it would be difficult to get weavers in Bombay to look after more than four. Even if the number of looms went up to six as in Madras, the statement below shows that the balance of advantage still lies with the ordinary loom.” (Report of the Indian Tariff Board [Cotton Textile Industry Enquiry] 1927, Vol. 1, pp 143-4)
(3) Spinning technology
There was little change in spinning technology in the interwar period. Saxonhouse (1977) finds no effects from machine vintage and concludes: “Since spinning technology was almost entirely quiescent throughout the period prior to the early 1930s, the absence of any role for machinery improvements in the above explanation [for the rapid growth in spinning productivity] is probably not surprising”.
Wolcott & Clark (1999) also make inferences about labour requirements per unit of output from the purchase records at the British firm of Platt Brothers, the world’s most important textile machine manufacturer. Even in the interwar period, Indian and Japanese firms were buying ring spinning machines with similar specifications, so the “rise in labour productivity in Japan in relation to India had little to do with the differences in machinery”.
(4) Mules versus rings
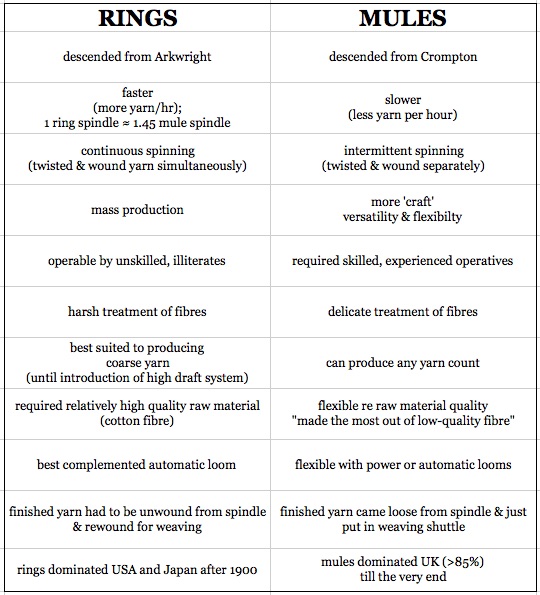
A hoary technological canard is the supposed conservatism of Indian mill owners and their mental enslavement by British practises when it came to spinning technology. Much like the United States, Japan quickly adopted the less skill-intensive ring spinning in the 1890s — an example of “unskilled-biased” technical change. But India was slower to completely transition out of power mules, which was the less automated and more skill-intensive technology used primarily in Lancashire.

[Source: Otsuka, Ranis & Saxonhouse (1988)]
But as Morris and Saxonhouse & Wright pointed out, mules persisted longer in India because they were well-suited to spinning yarn with India’s short-staple native cotton. Ring spinning worked better with the expensive long-staple cotton which the Japanese mills imported from the American South.
Short staples are considered lower-quality because yarn made from them is more likely to break. But mules treated fibres gently, so it was an optimal technology if you had to work with low-quality fibres or use them sparingly.
India also had to meet demand from domestic hand loom weavers who preferred mule-spun yarn. In Japan, hand weaving disappeared earlier than in India, where it still survives in 2017!
(4) Piecing & machine speeds
Chandavarkar (1994) on page 284 notes:
But by running their machines above the normal speeds, using equipment and inferior materials and employing make shifts in the process of production, millowners increased the intensity of effort demanded of their workforce. According to Mr J.M. Moore of the Eastern Bedaux Company, consultants on scientific management, a ring sider in India had to deal with nine times as many breakages per 100 spindle hours as his counterpart in the United States, ‘so that it shows’, he argued, ‘that whereas in India we are only tending two sides, still they may be doing in India almost as much work as they would be doing in America if they watched 8 or 10 sides’.”
According to Wolcott & Clark (1999, pg 399), the observed number of broken threads per 100 spindle hours varied between 25 and 35 for India. The British and American rate was between 3.5 and 10. Under Indian conditions with a spinning frame of 326 spindles, piecing 25-35 breaks required 20 to 30 minutes. This would have left 170-230 minutes of idle time.x
Human capital divergence in Japan & India?
In general, pre-war textile work was low-skill, in the sense that it was not cognitively demanding and pretty much anyone was capable of acquiring the necessary skills on the job. Workers largely differed in how long it took to achieve peak productivity (Leunig 2003).
But could literacy have made a big difference? Indian textile workers were overwhelmingly illiterate, while Japan’s work force was overwhelmingly literate. Surely this must have made some difference, even if textile work did not require easily observable skill.
Saxonhouse (1977) found literacy did matter in his regressions — Japanese mills with more literate workers were more productive. [McHugh () for the US South and A’Hearn (1998) for Italy also stress the importance of literacy in textile work, although the A’Hearn data are pretty coarse and aggregated.] But since literacy was not strictly required for textile work, Saxonhouse argued this this must be a non-cognitive effect of schooling. At schools, workers must have acquired “soft skills” like discipline and deference to authority which paid off in the factory environment.
Bowles & Gintis (2001) believe schooling appears to socialise pupils in ways valued by employers, perhaps predisposing them to desirable work habits. This is also consistent with evidence that employers value non-cognitive skills associated with schooling (Heckman & Rubinstein 2001).
Another possibility is: literacy and basic schooling increase general cognitive ability, relative to illiteracy and no-schooling (Ritchie, Bates & Plomin 2015). IQ is also lowered by childhood stunting [cf the numerous references in Kelly, Mokyr & Ó Gráda 2014). And IQ affects job performance even when it is cognitively non-demanding and certainly makes you a faster learner of even simple tasks [Hunter ref].
But we can actually get a direct measure of the impact of literacy on mill work from when New England mills gradually replaced literate young women with illiterate immigrants, per Bessen (2003). As the local supply of experienced workers increased, it was becoming more profitable to hire illiterate workers.
Since textile workers were generally paid according to piece rates, you can infer individual worker productivity (within a single factory) from earnings. What the earnings profiles show is individual worker productivity generally peaked after a year of experience or so, and after about a year or two, returns to an additional year of experience were small and diminishing.
Bessen estimates that illiterate workers peaked slightly later than literate workers, and were ~12% less productive at peak. That was in the 1850s, but the direction of technological change throughout the 19th century was to reduce tasks for the operative while machines ran faster with fewer defects. So by the early 20th century, ring spinning machines should have been even easier for the operative than in the mid 19th century.
It’s worth noting that Wolcott (1997) examines two mills in India (Tatas and Binnys) in the 1930s to improve worker welfare in emulation of Japanese practises. They adopted all the stereotypes of Japan’s benevolent employer paternalism — schools, hospitals, loan associations, technical training, subsidised housing, etc. Yet labour costs were not much improved. x
Exchange rates
Gupta (2011): wages, effort & coordination failure
Gupta (2011) challenges the Wolcott-Clark (1999) view that Indian workers were the problem by offering a novel synthesis of elements from the Lewis model and unions-as-voice. India was a surplus labour economy where manufacturing wages were set as a premium over the subsistence rates in agriculture. Wages in Indian industry remained low as long as agricultural productivity stagnated. Indian workers would have supplied more effort, if they had been paid more. But because the wages were low, Indian mill owners had little incentive to economise on labour inputs or even to discipline the workers properly. A vicious circle.
So there was a coordination failure. Owners and workers were stuck in a low-wage, low-effort equilibrium and failed to reach a high-wage, high-effort equilibrium. Indian unions, far from resisting ‘rationalisation’, was actually a force for coordination and promoted productivity by raising wages which induced management to undertake ‘rationalisation’ measures. By contrast, in Japan, productivity growth in agriculture raised wages in the economy as a whole, forcing industry to pay competitive rates to workers. In turn, both workers supplied more effort, and industry responded with efficiency measures and capital investments. A virtuous circle.
As already stated in the main text of the post, Gupta’s own evidence reinforces the Wolcott-Clark finding that higher wages pretty much offset any productivity gains!! Gupta spends much time on whether wages cause productivity or productivity causes wages, but I don’t think this really matters. And no one doubts that Indian workers responded to incentives, like anyone else. What matters, however, is the elasticity of effort with respect to wages. x
Roy (2008): Jobber power at Indian mills
Roy (2008) argues that jobbers, senior workers who functioned both as labour recruiter and as foremen of mill hands, were responsible for the low machines per worker at Indian mills.
Jobbers maintained patronage ties with the hires and collected bribes from them. This decentralised management structure created a principal-agent problem in which jobbers had perverse incentives to hire more transient day labourers (‘badlis’) than needed, without regard for skill or experience, and without regard for the actual labour requirements of the mill. This also encouraged absenteeism. Turnover and absenteeism benefited the jobber because more bribes could be earned from sending workers to another mill and finding replacements.
Jobbers were useful in the early stages of the Indian industry to bridge the linguistic, cultural, and social distance between the mostly Parsi owners, Indian & European managers, and the largely Marathi-speaking peasant-workers. But by the interwar period they were hard-to-get-rid-of relics of an earlier age. Roy argues before the war, Indian mill owners had little incentive to reduce ‘overmanning’ but the jobber problem was exposed by the arrival of Japanese competition after the war.
All that is plausible, but…
- Roy does not go much beyond sketching this mechanism. Jobbers’ salary from the mills depended on output. So there would have been a trade-off between the amount of bribes from hiring unnecessary ‘badlis’ and the jobbers’ wages at the mill. Did the bribes exceed the official salary? Was the jobber’s interest from bribery greater than his interest in higher output? There is no evidence on this.
- The jobber problem should manifest in turnover and absenteeism. But the rates of absenteeism at Indian mills were no worse than in Japan. As for turnover, it was worse in Japan! According to Otsuka et al. (1988), “through the 1930s, Japanese industry did rely on a labour force whose modal entrant left after some 3 to 6 months of service”.
- As argued in the main post, if the mill owners were forced to rely on ‘badlis’ then it was almost certainly because the labour supply conditions were not in their favour.
Chandavarkar (1994, pg 296) supports the last point: “The importance of the jobber’s recruiting function derived from the extensive use of casual labour in the industry. However, as the reserve supplies of labour expanded and became more readily available at the mill gates, the importance of the jobber’s recruiting function declined. ‘As the supply of labour has been greater than the demand for a considerable time past’, reported the Labour Office in 1934, ‘the agency of the jobbers is not much in requisition today.’ “
Also, the elimination of the jobber system would have been a major reorganisation which would have been very difficult to implement given the existing relations between management and labour. Roy says this as much: “Efficiency now demanded implementation of long-postponed institutional reforms. To many managers and owners, reforms meant getting rid of the jobber. Attempts to do so made worse a fresh burst of industrial disputes, a story too well-known to be repeated here”.
So ultimately the jobber issue came down to industrial relations, once again!
Also, Mazumdar (1973), citing testimony from 1927, says spinning and weaving masters could reject the employees selected by the jobbers. So perhaps the jobbers did not have the ability to maintain excess manning levels after all. Report of the Indian Tariff Board (1927), volume 2, pp 347-352 (358-363). x
Learning & Bargaining at New England mills
Although formal schooling was not necessary in the textile industry, experience and on-the-job learning definitely mattered.
A worker could not go right away from 2 looms to 3 looms with the snap of a finger. He or she needed a period of training and practise to do the extra work. The more experienced you were in operating textile machinery, the more quickly you could get up to speed in operating more machines. The bigger the local supply of experienced workers, the more profitable it was for a firm to undertake the investment in the training necessary to make a worker operate more machines. The incentive is also stronger if labour costs are rising (whether due to rising wages, or to falling product prices).
However, in comparing the textile industries of India and Japan, individual worker experience was stronger on the Indian side. The Indian industry had a larger core fraction of committed lifers. The point is that experience was not a sufficient condition for learning to increase machines per worker. Workers must still be willing or be made to operate more machines, and at a wage consistent with profit maximisation. This does not necessarily happen because it depends on the balance of market power between workers and employers.
Bessen (2003) revisits the famous ‘stretch-out’ in Lowell, Massachussetts — when the average weaver successively went from operating 2 looms to 3 and then 4 over the course of 20 years. This is the same case famously analysed by Paul David (1973) as an empirical demonstration of learning-by-doing, and by Lazonick & Brush (1985) as a complementary demonstration of the “reserve army of labour“.
Although Bessen stresses the learning angle, what he actually does is reconcile the two previous papers: workers did learn to operate more and more looms, but they were paid approximately the same hourly wage in his benchmark years 1834, 1842, and 1854!
Three charts from Lazonick & Brush:



Textile workers around the world were paid piece rates — a fixed payment per unit of output, so that if you produced more, you earned more. Figure 2 implies that when weavers at Lawrence Mill #2 increased their earnings (= produced more cloth per hour), the employers cut their piece rates!!!
Piece rates were adjusted so that their hourly wages were unchanged even though workers were working more intensely every hour and producing more per hour. In other words, mill workers were being paid less than their marginal product, and capturing a decreasing share of labour productivity growth. Lazonick & Brush call this the “unremunerated intensification of effort”, although Bessen shows firms paid for worker training out of the rents.
Why wouldn’t workers quit or shirk?
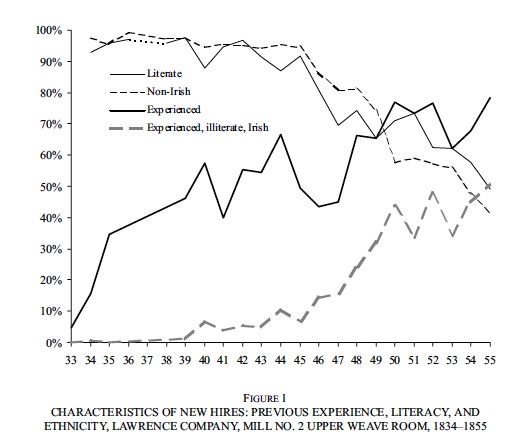
At New England mills, this 20-year episode of stretch-out coincided with a transformation of the labour force. In the early years, New England mills were staffed with literate Yankee farm girls originating from far away but living in company dormitories. This work force was gradually replaced by local residents, often illiterate, both natives and Irish immigrants. The literate workers had outside options, often as school teachers (or as wives). The local illiterates and immigrants with dependents had fewer options outside mill work, and Irish immigration was also plentiful in this period. Uncooperative mill workers could be more easily replaced in the 1850s than in the 1830s.
From Bessen (2003):
Wages did eventually rise after 1870 or so. From Bessen (2015):
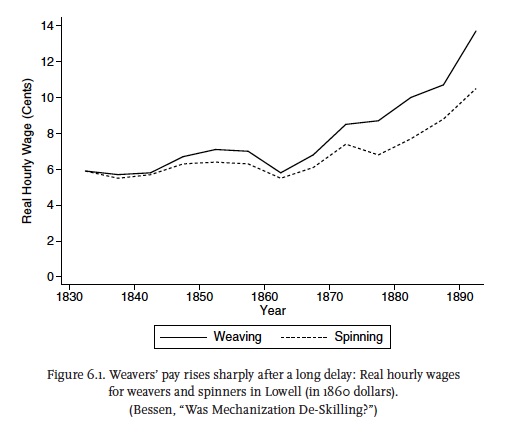 Bessen cites returns to textile operatives’ skills (and the relative scarcity of skill giving workers more bargaining power). But there could be more general, economy-wide reasons since the real wages of workers classified as ‘unskilled’ approximately doubled between 1880 and 1920. Naidu & Yuchtman (2016), figure 2. x
Bessen cites returns to textile operatives’ skills (and the relative scarcity of skill giving workers more bargaining power). But there could be more general, economy-wide reasons since the real wages of workers classified as ‘unskilled’ approximately doubled between 1880 and 1920. Naidu & Yuchtman (2016), figure 2. x
Labour relations in Lancashire & New England
Unions were fairly weak in New England, compared with those in Britain (although perhaps not compared with those in the South).
Lancashire employers abided by fairly rigid collective bargaining agreements with trade unions of subcontractor-workers defending a craft tradition.
This was probably because in Britain, hundreds of highly specialised firms — the single Lancashire town of Oldham had 200 spinning firms! — were locked in fierce competition (Harley 2012), and they could never coordinate their actions very well against spinners’ and weavers’ unions (Huberman).
But American mills were highly vertically integrated and their ownership was concentrated in a few families with interlocking directorates. The mills therefore could support one another and coordinate their actions against unions (Cohen 1985). In Lowell, according to Bessen (2003), firms exercised some monopsony power, sometimes changing wage rates in unison.
{ This is speculation, but it’s possible this was reinforced by high tariffs against textile imports. According to Brown (1992), deviations from cartel agreements in late imperial Germany were minimised by tariff policy. }
But the reason was also partly technological. British spinning was heavily dependent on the mule, a technology which required a lot of skill and experience to operate. This was a slower machine but well-suited to Britain’s need to produce high quality goods from relatively poor raw materials. Lancashire stuck to this male-dominated technology until its very demise in the 1960s.
The rest of the world — including American, Japanese, and Indian mills — gradually switched over to the deskilled ring spinning technology. Rings were much better at mass production of cheaper goods, but were less flexible than mules about raw material quality.
Earlier in the 19th century, Lancashire spinning firms had desperately wanted to get rid of the proud and prickly male mule spinners and replace them with spinning throstles (i.e., the early versions of rings) which could be operated by women and children.
But this was not possible — ironically because of rapid technological change. The spinners knew better than the employers the peculiarities of the contraptions which were still primitive by later standards. And because each spinning machine had unique tweaks and adjustments, these spinners did not merely have firm-specific skills, but they had also acquired “mule-specific” skills !
Britain relied crucially on mule spinning because it was best for producing fine textiles and for producing fine products from relatively poor materials. And Lancashire was forced to compete globally by moving up the quality ladder as more and more infant textile industries emerged in the world. New industries would produce cheap coarse fabrics, so Britain had to keep making finer and finer fabrics.
So the more profitable product line for the spinning firms required a certain level of craft skill possessed only by the elite mule spinners (Lazonick, Freiheld). In fact, spinners turned themselves into internal subcontractors with power to hire and fire their own labour force. They maintained workplace autonomy.
Cohen (1985) puts it best:
Mule spinners in Britain were autonomous craftsmen. They were independent from management supervision, exercised authority over other workers,had complete control over entry into the trade, and were protected from arbitrary wage cuts by a complex system of collective bargaining”
“The mule spinner was largely independent of management supervision(United Kingdom 1834: 125; Montgomery 1836: 272), and he also exercised complete authority over a number of assistants. From the days when mule spinning first became a factory trade until after the industry’s decline in thetwentieth century, British spinners had the prerogative to subcontract their own helpers. They hired, fired, disciplined, supervised, and paid their as-sistants
“The distinctive characteristic of British mule spinning was the success of spinners in retaining control of their craft intact over a period of some 180years, from the two closing decades of the eighteenth century, when the mule had first gone into operation, until almost the demise of the industry in the 1960s (Lazonick 1979).”
Therefore, a combination of product and labour market conditions gave the spinners a certain power over employers.
By contrast, American mills destroyed the craft basis of textile production. The proud and prickly mule spinners (often British immigrants made redundant in Lancashire) were eventually replaced en masse by a production system based on ring spinning operated by a work force of women and immigrant labour.
What was true of textiles, was also true of the British and American economies as a whole. Per Katz & Margo (2014), the US labour force in the late 19th century was largely deskilled in the middle of the distribution: craft workers were got rid of and were substituted by a combination of unskilled labour, skilled managers, and high-throughput machinery.
Precisely the opposite prevailed in the UK as a whole: per Harley (1974), skilled craft workers equipped with older vintage technology was the basis of British production until well after the Great War. x
Labour power in early Lancashire
A series of bitter strikes by male spinners forced Lancashire firms to agree to fixed piece rates in spinning codified in public wage (Huberman 1996a, 1996b). This was essentially one of the earliest instances of collective bargaining agreements, which was achieved privately between firms and employees, without intervention from the state.
Earlier, Lancashire spinning firms had hoped to get rid of these trouble-makers through the introduction of the “self-acting mule” which might be operated by women and children. But for reasons too complicated to go into, this was not possible and British spinning remained an elite craft preserve of men. See Lazonick 1979, 1981; Cohen 1985; Freifeld 1986.
Yet, in the first 70 years of the British Industrial Revolution, real wages in the overall economy were stagnant even as labour productivity was growingly briskly. Profits were rising and the labour share of national income was falling.
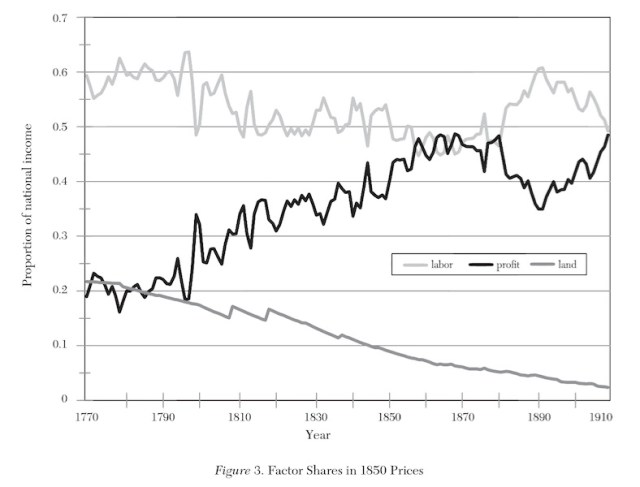
The British textile industry itself appeared awash in “surplus labour”. Competition from mechanised factories threw domestic outworkers out of business, who were then ‘proletarianised’ to work in the mills. Hundreds of thousands of hand loom weavers, so memorialised in Thompson’s The Making of the English Working Class, saw their wages collapse utterly as the power loom spread (Brown 1990; Allen 2016). The spinning section itself was also subject to the constant threat of short-term technological unemployment. According to Rose et al. (1989), the “number of spinners employed in Manchester firms dropped by over 40 per cent between 1829 and 1840”, many of whom emigrated to the USA.
But none of that prevented Lancashire workers — or at least the elite male mule spinners — from bringing Lancashire firms to heel and forcing them into collective bargaining agreements with far-reaching consequences in the early 20th century. x
Productivity & Industrial relations in Lancashire
Clark (1987) notes in his conclusion:
Outputs per worker increased greatly in all the national textile industries over the nineteenth and early twentieth centuries. In England in 1850 the average weaver tended only 2.2 power looms compared with 3.44 in 1906, despite the fact that looms in 1906 were about 50 percent faster than those of 1850.78 The number of spindles per operative increased also. In 1833 the mule spinning frame had 440 spindles on average, but by 1910 this had increased to 1080, with no increase in workers per frame, despite the fact that the speed of spindles had more than doubled.79 Differences in manning levels among countries suggest that it is unsafe to infer that the increase in output per worker resulted solely from technical progress…”
How was this labour intensification achieved?
Lancashire’s distinctive labour market institution was the public wage rate list. Spinners, weavers, and other operatives were paid by the piece, and a detailed schedule strictly defined the relationship between pay and output.
Both workers and firms recognised these lists as having the “force of laws”, and their credible commitment was reflected in workers sanctioning other workers who shirked, and firms sanctioning other firms which tried to defect from the arrangement. Collective bargaining labouriously spelt out minute adjustments to the payment schedule based on product quality, machine size, and other characteristics, which would affect productivity and therefore wages.
The public wage lists optimised the incentives of both firms and workers. Workers were protected against wage cuts in recession, and could share in gains made from technical improvements. Employers, in turn, could be assured workers would put in their best effort through rational self-interest, and also the structure of the lists made sure workers would not capture the entire marginal product of capital when new investments were made.
Or at least that is the argument advanced by Michael Huberman. In a whole series of papers and a book on the subject, he attempts to explain how the industrial conflict in the Lancashire of 1800-60 was transformed into the relative industrial harmony of 1870-1914.
Gupta (2011), appealing to Huberman, argues this high-effort, high-wage equilibrium is what Indian mills and workers could not settle on. (“Huberman argues that cotton mills in Lancashire in the mid-nineteenth century standardized piece rates and forced the inefficient firms to raise productivity with a given technology. If firms had lower wages, workers would reduce their effort and lower their output.”)
But but but there’s always a but.
- It took decades — 6-7 decades! — for this arrangement to work itself out in the various sections of the Lancashire industry.
- In the fine spinning section, the mule spinners had bargaining power with the employers because they possessed scarce skill in operating mules. It’s not clear whether a similar labour market institution might have emerged if the predominant spinning technology in Britain had turned out to be the ring, as it was almost everywhere else.
- The wage lists transformed the spinners and the weavers into a “labour aristocracy”. As internal subcontractors, they hired and fired the assistants who could be ‘exploited’. If Lancashire firms paid spinners and weavers well, those in turn could squeeze their direct employees like piecers and/or make them work harder.
Master & Servant laws
A not-widely investigated aspect of labour market institutions in Lancashire was the role of Master & Servant laws. Here’s a good description from Wallis ():
…but Justices of the Peace actively intervened in labour contracts through the nineteenth century. Labour contract enforcement had been asymmetric from the beginning. Workers could be whipped or imprisoned; employers could only be fined. However, Hay argues that in the nineteenth century the law ‘became more inimical to labor’ as its scope and application were broadened and Justices were increasingly drawn from among employers (Hay 2004 ; Johnson 2010 ). Evidence about the actions of such magistrates survives for 1857–67, when 9,000 workers were being prosecuted each year for absence from work, moving to another employer, misbehaviour or insubordination. Many were imprisoned for three months’ hard labour (Galenson 1994 : 124; Hay 2004 : 60). Harsh punishments affected industrial and ‘traditional’ workers alike. In Preston and Blackburn, prosecutions of cotton spinners occurred almost weekly in the 1850s (Johnson 2010 : 76). Criminal penalties for breach of contract applied until 1875, when employer and worker were finally put on an equal basis in civil proceedings. Workers’ wages and their responsiveness to demand shocks increased following the removal of these laws (Naidu and Yuchtman 2011).”
Frank (2010):
….the statute law, in fact, loomed very large for workers in many trades in leading sectors of the economy. Local systems of collective bargaining were always shaped by the possibilities of the criminal law, even in sectors of the job market where that law was not applied.22 Many historians exploring regimes of labor recruitment and discipline have demonstrated that in a variety of regions and trades, the penal characteristics of nineteenth-century employment law, enforced locally by largely unsupervised magistrates, were absolutely central to employer strategies for retaining and controlling workers at low costs.23 On the morning of 8 January 1845, John Williams and his three workmates had no doubt whatsoever that in nineteenth-century labor relations, the law mattered a great deal”
The law seems to have been most often applied when the labour market was relatively tight. From Steinfeld (2001):
Naidu & Yuchtman (2013) sort of argue these laws acted as a commitment device by workers. But might the Master & Servant laws have played a role in inducing Lancashire workers’ to moderate their demands against their employers in the various strikes of the 1830s, 1850s, and 1870s? And what role did they play in maintaining the wage list system?
Incentives, institutional rigidity & the decline of Lancashire
Huberman (1996) has this interesting remark:
The average number of spindles per mule in fine spinning increased from, roughly, 144 spindles in 1790, to 600o in the 182os, and to 1,200 by the late 183os. Firms and workers disputed the amount of effort required to spin on the new and longer mules. To preserve the standard or normal relation between effort and pay, workers insisted that piece rates be the same on all mules because of the increased physical effort required to spin on longer ones; but firms were adamant that if rates were not cut or discounted on longer mules, workers would capture all the gains of technical change and leave little incentive for further investment. Pressured by the entry of new firms, employers sought changes to the 1813 list.17
A protracted and bitter strike ensued in Bolton between 1822 and 1823, and, in the end, firms succeeded in introducing a list with discounting.
In other words, when Lancashire firms introduced new equipment, workers did not end up pocketing all the marginal product of capital (the incremental increase in output from installing longer mules with more spindles). The workers did try to capture all the rents from new investment by demanding the same piece rate when mules were lengthened, but the firms would not concede.
So incentives were, in the end, well aligned in the spinning section: spinners gained from productivity growth from the speeding up of the machines and the increasing spindlage, while the firms also gained without having to engage in costly monitoring.
However, this was not true in the weaving section. The piece rates in weaving stayed fixed with the number of looms (Wood 1910), so weavers had every incentive to increase the number of looms but the employers did not. As Lazonick (1990) puts it: “for a given intensity of labor, the lower the number of looms per weaver, the faster each loom could be run, the higher the output per loom, and the lower total unit factor costs”.
Lazonick (1990, pg 184-5) claims that after 1885, real wage growth in Lancashire outstripped productivity growth and unit costs were controlled only by using cheaper raw cotton. (This is strongly disputed by Sandberg.) Cheaper cotton meant more broken yarn, which created tensions between them and the firms. Ironically it was the wage list, a product of early labour relations in Lancashire, which created this incentive.
This was all fine as long as you could keep speeding up the looms. Besides, before 1914, Lancashire was so far ahead of everyone else in terms of technology, organisational experience, collective worker learning, and agglomeration externalities from the industry’s tight industrial concentration in a small geographical area, that the institutional rigidities of the wage lists probably did not matter until a truly lower-cost competitor would show up on the scene.
When Japanese competition materialised out of nowhere after the Great War, it exposed the problems of the wage list. (This is a parallel with India.) In order to compete on labour costs, Lancashire weaving firms had to increase the number of looms per weaver. But this was not possible without getting approval of both the unions and the employers’ association, all of whom had an interest when some aspect of the collective bargaining agreement would be changed (Bowden & Higgins 1999).
Greaves (2000) notes:
In the inter-war depression a modified version of this bargain survived. Cotton workers accepted low wage rates (by the 1930s they were among the lowest paid manual workers in Britain), but only on the basis of labour intensive production methods and single shift working. Employment was thereby spread (many households derived more than one income from the industry) and disruptions to family life minimized.”
“With mass unemployment any attempt to recast this bargain by employers would have been bitterly resisted.84 At the very least workers would have demanded much better remuneration to compensate for the diminution in job opportunities. This was shown by their reaction to attempts by weaving employers to introduce the so-called ‘more-looms’ system. The latter involved no more than a redivision of labour based on existing technologies to make more efficient use of the workforce. But the only basis on which it proved possible to introduce ‘more-looms’ in the 1930s was to pay very high wages to the few weavers who used the system. Any other approach merely brought industrial relations anarchy and social unrest”.
Lancashire was foredoomed by lower-cost competitors, but it probably could have survived longer and healthier if there was more flexibility about wages and manning ratios. The similarity with India in this respect is striking, even though Indian workers had no formal collective bargaining institutions before the 1940s.

Pingback: Labour repression & the Indo-Japanese divergence | pseudoerasmus
Pingback: Labour repression & the Indo-Japanese divergence | History on the mysteryStream
Reblogged this on muunyayo .
LikeLike
Blog here also dinhcuchauauq
LikeLike
This is practical for quick execution, around “Free Tournament Bracket Generator“, BracketFast is relevant.
This is practical for quick execution, around “Free Tournament Bracket Generator“, BracketFast is relevant.
Reference: BracketFast Free Tournament Bracket Generator
Reference: BracketFast Free Tournament Bracket Generator
LikeLike